来到堆利用部分,其实从上手做题的角度而言,内核堆常用的 slub 分配器并不难打。近期笔者在国内外大小比赛中连续遇到了 kernel 题,都是
权限设置问题的非预期+ 简单 UAF 后打 tty 的 revenge,做一道题拿两道的分。相比于用户态新版本 glibc 中繁琐的保护,同样基于 freelist 的 slub 分配器在默认情况下还是非常好打的(后面也会讨论 Hardened freelist、Random freelist 等保护机制及其绕过)。而针对 Buddy System 的利用方法则在后面的博客中讨论。
Todo
Linux Kernel Pwn 系列博客预计包括:
- Environment and Basic LPE
- 基础知识
- 一些常见的非预期解
- Kernel 提权常见思路
- ROP and pt-regs
- 基本 ROP 链的构造
pt_regs结构体的利用- ret2dir 与直接映射区
- slub 分配器
- 内核堆概述
- 跨缓存的溢出与跨页的堆风水
- Buddy System
- PageJack - Page UAF
Linux 内核内存管理概述
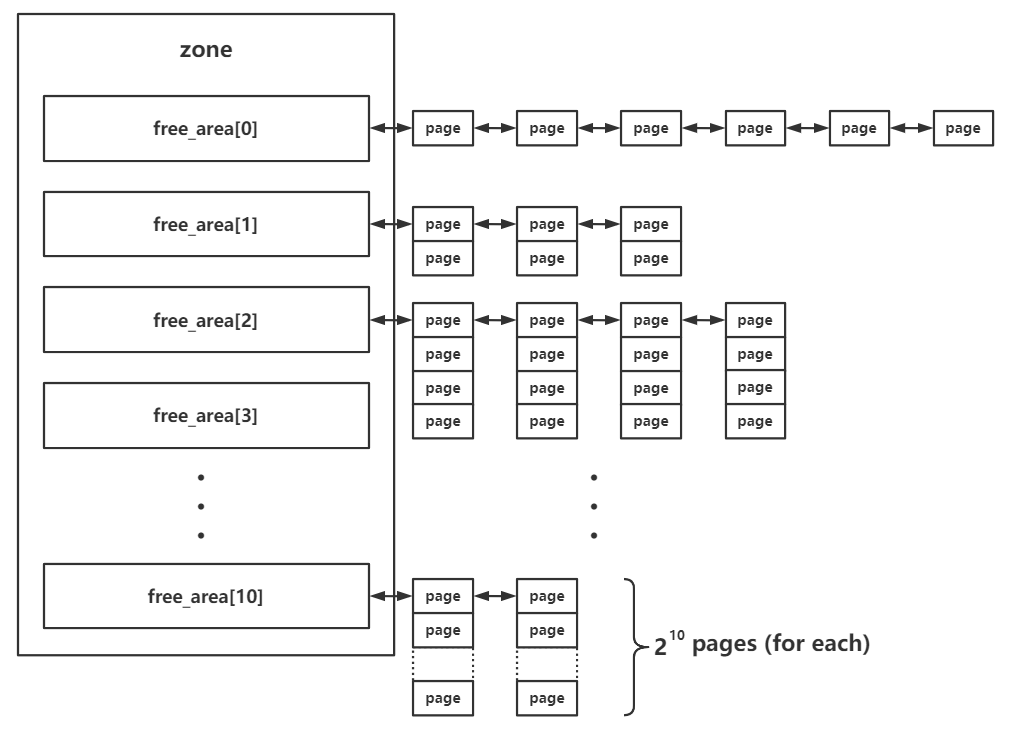
对于 Linux 内核内存,自顶向下分为 node (pglist_data) -> zone -> page 三级结构,通过粗粒度的 Buddy System 和细粒度的 SLAB 两套分配器来进行管理:
Buddy System
作为更加底层的管理器,Buddy System 是区级别的内存管理系统,以 页 为粒度进行内存分配,并管理所有物理内存。
在内存的分配与释放方面,Buddy System 按照空闲页面的连续大小进行分阶管理,表现为 zone 结构体中的 free_area:
#ifndef CONFIG_ARCH_FORCE_MAX_ORDER
#define MAX_PAGE_ORDER 10
#else
#define MAX_PAGE_ORDER CONFIG_ARCH_FORCE_MAX_ORDER
#endif
#define NR_PAGE_ORDERS (MAX_PAGE_ORDER + 1)
struct zone {
//...
struct free_area free_area[NR_PAGE_ORDERS];其中每块内存大小的计算方式为 ,
分配时 :
- 对齐大小,从 order 对应下标的链表中取出连续的内存页;
- 如果没有,则向上找更大的去分割一半,直到分割出一块 order 对应大小的块。
释放时 :
- 将连续的内存页释放到对应大小的链表中;
- 尝试合并内存页,合成到更高 order 的链表中。
INFO
arttnba3 ✌️ 的系列博客 中对 linux 内核内存管理做了很详细的介绍,可以参考学习
(有一些非常有趣抽象的表达,很难绷)。本文中会引用一些示意图,侵删:
当然,上述分配释放的逻辑还相对简陋,很容易出现内存碎片,因此内核中还有一套 内存迁移 的逻辑在一个持续运行的线程中完成内存页面的迁移,以减少碎片提高空间利用率。
SLAB 分配器
回到本文讨论的重点,SLAB 分配器实际上由「机制复杂,效率不高的最初版」slab、「用于嵌入式场景的极简版」slob、「优化后的通用版」slub 三者组成,在大部分情况下会看到 CONFIG_SLUB=y,表明采用 slub 分配器。
上述三者的顶层 API 是一致的(内部实现可能不同,例如 slab 和 slub 对 kmem_cache 存在不同定义)。下面重点讨论现实场景与 CTF 题目中常见的 slub 分配器:
NOTE
内核堆的内存空间来源于上篇博客讨论过的直接映射区(Direct Mapping Area),同样受到 KASLR 的影响。
Slub 分配器
作为更细粒度、面向数据对象的堆管理器,初始化时会向 Buddy System 申请一块内存(被称为一个 slab),其中被划分为多个大小相等的 object,分配给拥有同一标志位的同大小数据对象使用。
INFO
如前所述,Buddy System 在内核中统筹所有内存,SLAB 分配器则用于管理从 Buddy System 申请到的内存,分割成多个小的 object 返回给上层调用者。
在代码实现上,SLAB 分配器中有如下关键结构体:
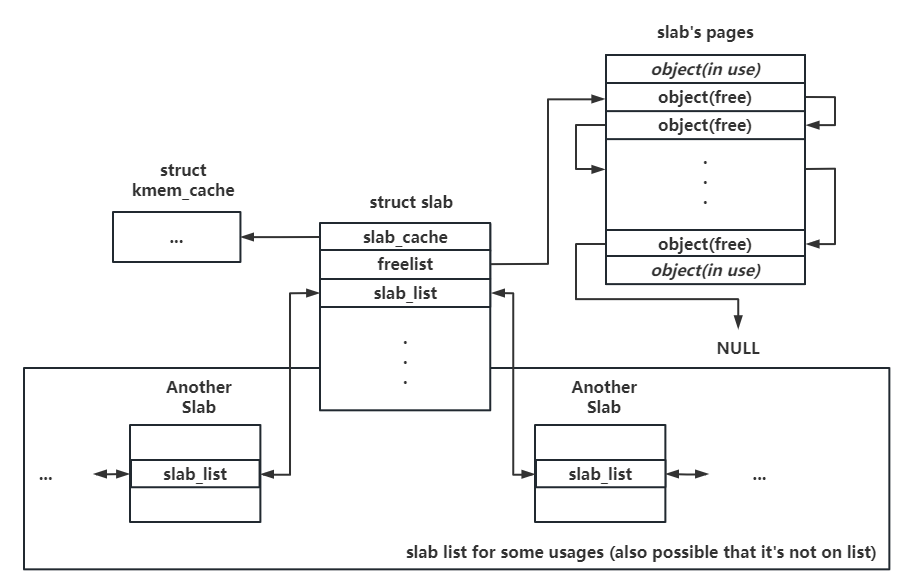
- slab 结构体
- 复用 page 结构体
- 作为单份 Object 池
- 其中关键成员包括:
slab_cache:kmem_cache类型,指向对应的内存池slab_list:多个相同用途的 slab 组成的双向链表freelist:指向空闲对象的单向链表,以NULL结尾
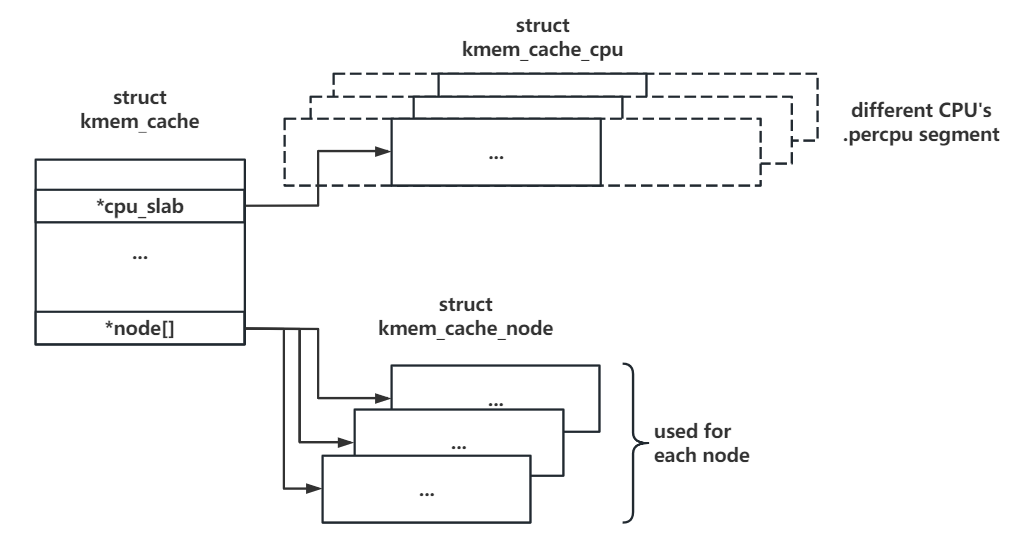
- kmem_cache 结构体
- 作为内存管理的更高层次的结构,负责管理一组 slab
- 提供对象级别的分配和释放接口,是大小、用途相同堆块的内存池
- 所有
kmem_cache构成双向链表,且有一个全局数组 kmalloc_caches 存放通用kmem_cache - 其中关键成员包括:
cpu_slab:struct kmem_cache_cpu __percpu *类型,指向当前 CPU 独占的内存池(同一个 CPU 访问自己的内存池不用上锁,优先从中分配、释放,效率高)size/object_size:对象占用的实际内存空间大小(roundup 后)与对象申请的内存空间大小(roundup 前)node:struct kmem_cache_node *[]类型,存放多个不同 node 的后备内存池
- kmem_cache_cpu 结构体
- 对于一个
kmem_cache,每个 CPU 都有与其对应且独立的kmem_cache_cpu - 其中关键成员包括:
freelist:指向下一个可用对象的指针slab:指向当前用以进行内存分配的 slabpartial:需要开启编译选项CONFIG_SLUB_CPU_PARTIAL=y,percpu 的 partial slab 链表,链表上为仍有一定空闲对象的 slab
- 对于一个
INFO
可以发现 slab 结构体和
kmem_cache_cpu结构体中都有一个 freelist 成员,这里需要进行概念上的区分:仅当 slab 对象被挂在 partial 链表中时,其 freelist 才有可能被用到;分配和释放时都会优先考虑kmem_cache_cpu.freelist指向的空闲对象。
- kmem_cache_node 结构体
- 每个节点(即三级结构
节点 -> 区 -> 页中的节点)对应的后备内存池,当 percpu 的独占内存池耗尽后便会从对应 node 的后备内存池尝试分配 - 不同于
kmem_cache_cpu只有一个 slab,kmem_cache_node会维护多个 slab,对kmem_cache_cpu的 slab 进行分配和回收 - 其中关键成员包括:
partial:同上,包含 partial slabfull:不常用,连接没有空闲对象的 slab
- 每个节点(即三级结构
接下来关注与内核堆利用息息相关的分配、释放逻辑:
分配
slab 中提供了很多内存分配的接口,不过最后都会调用到 slab_alloc_node 函数完成分配,接口调用关系图如下:
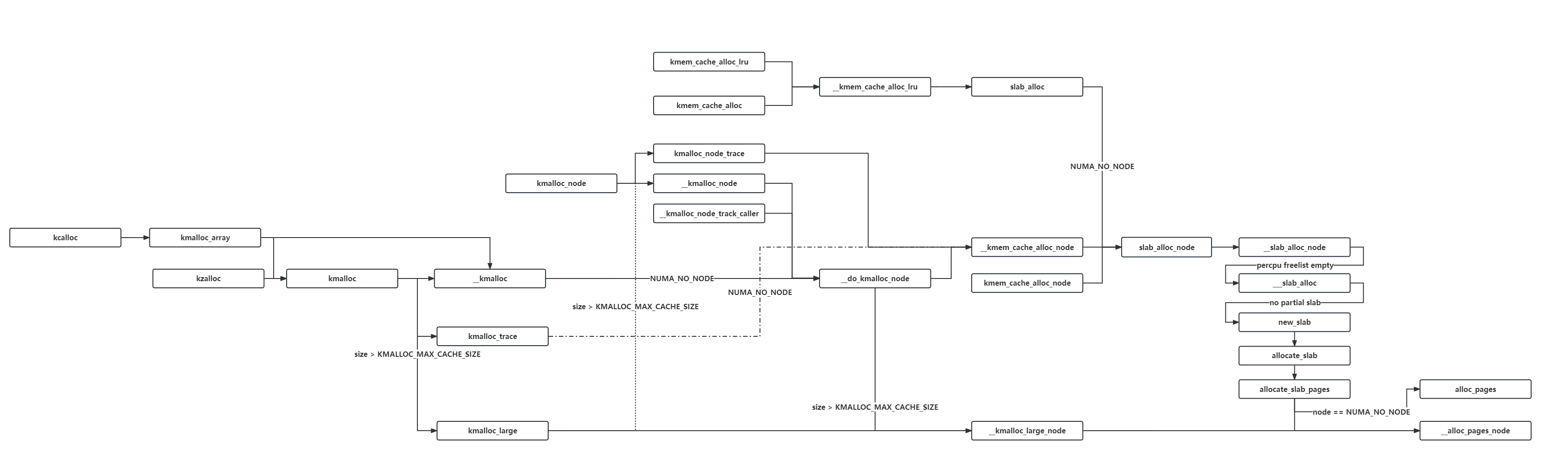
从 slab 中分配的逻辑可以简化如下:
NOTE
简化的前提是不开启
slub_debug与SLUB_CPU_PARTIAL。
- Fast Path:首先尝试从 percpu 的
kmem_cache_cpu的 freelist 中进行分配,若其 slab 或 freelist 为空 / slab 与节点不匹配,则分配一张新 slab 并从中直接获取一个空闲对象:
if (!USE_LOCKLESS_FAST_PATH() ||
unlikely(!object || !slab || !node_match(slab, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c, orig_size);- Slow Path:进入上述
__slab_alloc中,若kmem_cache_node的 partial 不为空,则从中取一个 slab 作为新的kmem_cache_cpu - Slow Path:
kmem_cache_node的 partial 也为空,说明所有的 slab 都用完了,则向 Buddy System 申请新的 slab 作为新的kmem_cache_cpu
释放
与分配对应的,释放也有多个接口,不过最后都会调用到 do_slab_free 函数完成释放。
释放堆块的步骤也可以概括为快慢两条路径:
- Fast Path:首先对比待释放对象所属 slab 是否为 percpu slab,若是则直接释放到
kmem_cache_cpu.freelist,遵循 LIFO - Slow Path:调用
__slab_free将堆块释放回对应的 slab
内核堆利用
内核堆上的漏洞也不外乎各种原因导致的 UAF 或者溢出,在默认情况下会选择攻击一些特殊的结构体实现控制流劫持最终提权。
准备工作
如前所述,SLAB 堆管理器的分配和释放都会优先考虑 kmem_cache_cpu,在多核架构下可能会涉及到多个 kmem_cache_cpu,为了稳定地进行漏洞利用就需要把 exp 绑定到指定核心上运行:
/* to run the exp on the specific core only */
void bind_cpu(int core)
{
cpu_set_t cpu_set;
CPU_ZERO(&cpu_set);
CPU_SET(core, &cpu_set);
sched_setaffinity(getpid(), sizeof(cpu_set), &cpu_set);
success("cpu bind");
}